Database design
VEMAP maakt gebruik van een relationele database gebouwd op PostgreSQL. Deze keuze is gemaakt in lijn met de gebruikelijke werkwijze van MAPtm en de eisen van de applicatie: onderhoud baarheid, overdraagbaarheid en schaalbaarheid.
Design principes
Section titled “Design principes”Data normalisatie
Section titled “Data normalisatie”De database is ontworpen volgens Third Normal Form (3NF) principes:
- 1NF: Alle kolommen bevatten atomaire waarden
- 2NF: Geen partiële afhankelijkheden van samengestelde keys
- 3NF: Geen transitieve afhankelijkheden tussen kolommen
Voordelen:
- Minimale data redundantie
- Consistente data updates****
- Bescherming tegen data anomalieën
- Eenvoudiger onderhoud
Multi-tenancy
Section titled “Multi-tenancy”De database ondersteunt multi-tenancy via tenants (voorheen client_environment):
- Isolatie: Elke client heeft eigen environment identifier
- Data segregatie: Queries filteren automatisch op
tenant_id - Schaalbaarheid: Nieuwe clients zonder schema wijzigingen
- Security: Row-level security door applicatie layer
Schema Scheiding
Section titled “Schema Scheiding”De database gebruikt twee schema’s voor scheiding tussen productie en ontwikkelomgeving:
public- Productie/klantdatadevelopment- Development/testdata
Deze scheiding zorgt voor:
- Data integriteit: Klantdata wordt beschermd tijdens ontwikkeling
- Veilige demo’s: Testdata kan gebruikt worden zonder risico voor productie
- Betere ontwikkelervaring: Ontwikkelaars kunnen vrij experimenteren zonder impact op productie
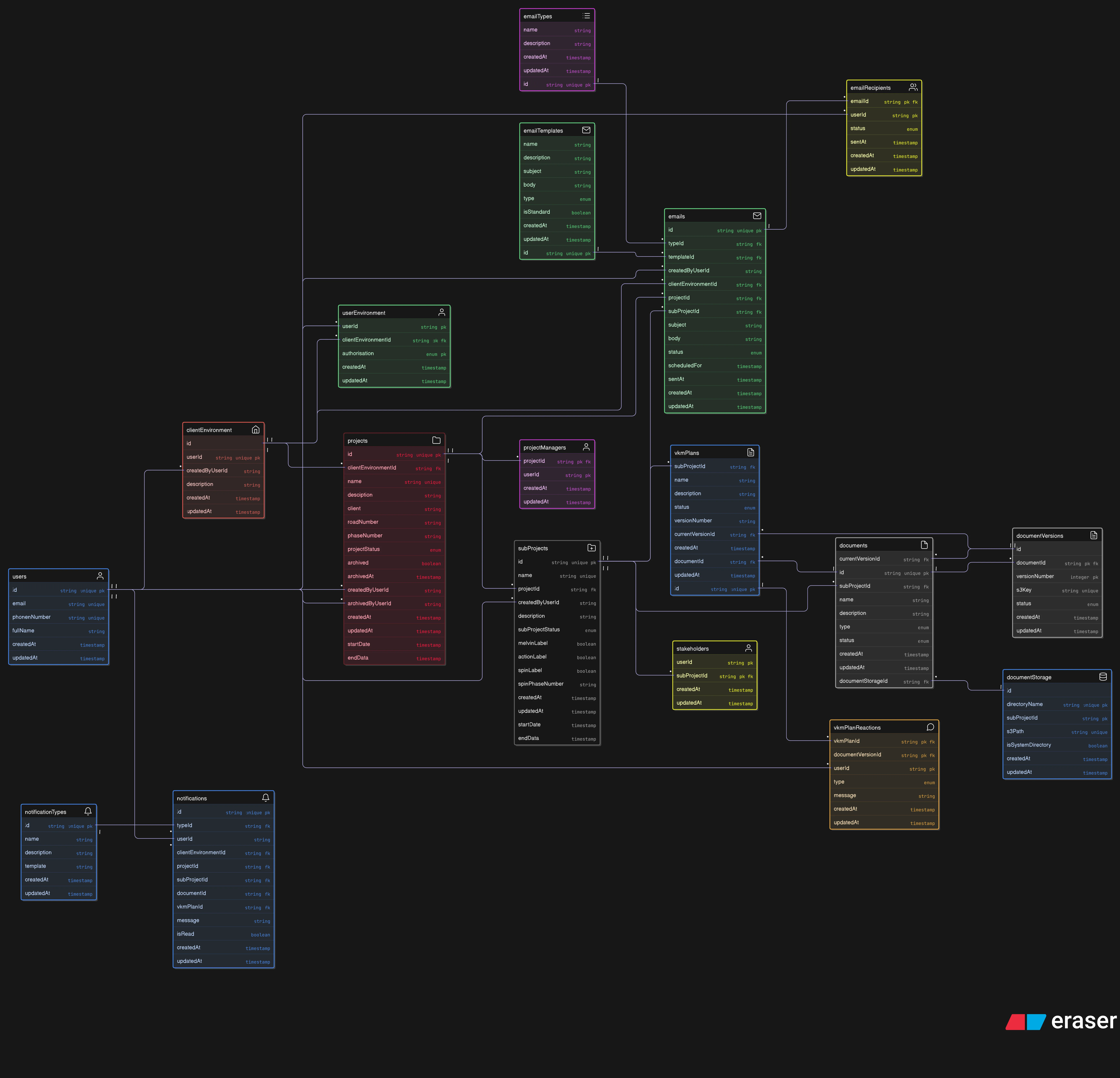
Entity relations diagram
Section titled “Entity relations diagram”Het ERD diagram toont de relaties tussen alle database tabellen en hun kardinaliteit.
Database architectuur
Section titled “Database architectuur”Hiërarchische structuur
Section titled “Hiërarchische structuur”Client Environment (root) └── User Environment (many-to-many) └── Projects (one-to-many) └── Closures (one-to-many) ├── Files (one-to-many) ├── Closure Stakeholders (many-to-many) └── Closure Comments (one-to-many) └── Project Managers (many-to-many) └── Project Recipients (many-to-many) └── Email Templates (one-to-many) └── Template Blocks (hierarchical) └── Files (client logos)Kern entiteiten
Section titled “Kern entiteiten”Klant en gebruikersmanagement
Section titled “Klant en gebruikersmanagement”tenants (voorheen client_environment)
- Root entiteit voor multi-tenancy
- Bevat bedrijfsinformatie en contactgegevens
- One-to-many relatie met projects en users
- Primary key:
id(uuid)
user_env (voorheen user_environment)
- Junction tabel voor users binnen client environments
- Bevat autorisatie niveau per environment
- Primary key:
id(uuid) - Foreign key naar
tenantsviatenant_id
Project hiërarchie
Section titled “Project hiërarchie”projects
- Centrale entiteit voor werkprojecten
- Bevat project metadata (wegnummers, fasenummer, etc.)
- Archivering ondersteuning
- One-to-many relatie met closures
closures (voorheen sub_projects)
- Afsluitingen binnen een project
- Bevat periode, type, en status informatie
- Labels voor Melvin, Action, SPIN tracking
- One-to-many relatie met files en comments
Documentmanagement
Section titled “Documentmanagement”files
- Centrale bestandsopslag voor alle document types
- Versie beheer met
versionenis_current_version - S3 integratie voor externe opslag
- Ondersteunt: VKM plannen, support documenten, client logos
- Soft delete met
is_archived
Email systeem
Section titled “Email systeem”email_templates
- Herbruikbare email templates per client
- Root block verwijzing naar template structuur
- Soft delete met
is_active
template_blocks (hierarchical)
- Boom structuur voor email layout
- Parent-child relaties voor nesting
- JSONB voor styles en properties
- Block types voor verschillende elementen
email_messages
- Verzonden email tracking
- Status tracking (sent, failed, bounced)
- SES message ID voor AWS integratie
email_message_recipients & email_lists
- Recipient management per project/closure
- Email list grouping voor bulk emails via
email_list_recipientsjunction tabel
email_recipient_delivery
- Delivery tracking voor email recipients
- Status tracking en error handling
- Timestamps voor queue, sent, delivered, failed
Samenwerking
Section titled “Samenwerking”closure_stakeholders
- Many-to-many relatie tussen closures en users
- Soft delete tracking met
is_deletedendeleted_at
closure_comments
- Feedback en discussie per VKM plan versie
- Type field voor verschillende comment soorten
- Gekoppeld aan specifieke VKM versie
project_managers
- Many-to-many relatie tussen projects en manager users
- Access control voor project beheer
project_recipients
- Email recipients specifiek voor project communicatie
- Gescheiden van closure recipients voor granulaire controle
Relatie types
Section titled “Relatie types”One-to-Many
Section titled “One-to-Many”Voorbeelden:
tenants→projectsprojects→closuresclosures→filesemail_templates→template_blocks
Implementatie: Foreign key in child tabel
Many-to-Many
Section titled “Many-to-Many”Voorbeelden:
users↔tenantsviauser_envprojects↔usersviaproject_managersclosures↔usersviaclosure_stakeholdersemail_lists↔recipientsviaemail_list_recipients
Implementatie: Junction/bridge tabellen met composite keys
Naamconventies
Section titled “Naamconventies”Tabellen
Section titled “Tabellen”- Lowercase met underscores:
tenants,user_env - Plural waar logisch:
projects,closures,files - Descriptive names: Duidelijk doel uit naam
Kolommen
Section titled “Kolommen”- Lowercase met underscores:
created_at,tenant_id - Suffix conventies:
_idvoor identifiers_atvoor timestamps_byvoor user referencesis_voor booleans
Constraints
Section titled “Constraints”- Primary keys:
<table>_pkey - Foreign keys:
<table>_<column>_fkey - Unique constraints:
<table>_<column>_key - Check constraints:
<table>_<column>_check
Indices
Section titled “Indices”- General:
idx_<table>_<column> - Composite:
idx_<table>_<col1>_<col2> - Functional:
idx_<purpose>_<table>
Data types strategie
Section titled “Data types strategie”UUID gebruik
Section titled “UUID gebruik”Waarom UUID’s voor primary keys:
- Security: Niet-sequentieel, moeilijk te raden
- Distributed systems: Geen centrale ID generator nodig
- Merging: Eenvoudig data van meerdere bronnen samenvoegen
- Privacy: Geen inferentie over record counts
Performance overweging:
- UUID v4 (random) gebruikt - 16 bytes vs 8 bytes integer
- B-tree indexes blijven efficiënt tot miljarden records
- Trade-off: grotere storage voor betere security
JSONB voor flexibiliteit
Section titled “JSONB voor flexibiliteit”Usecases:
- Template data: Email template structuur zonder rigid schema
- Properties & Styles: CSS-achtige configuraties
- Custom metadata: Uitbreidbaar zonder migrations
Benefits:
- Schema-less binnen gestructureerde tabellen
- Native PostgreSQL query operators (
->,->>,@>,?) - GIN indexing voor snelle JSON queries
- Validatie via applicatie layer (Pydantic)
Timestamps met timezone
Section titled “Timestamps met timezone”Strategie: Alle timestamps inclusief timezone
Voordelen:
- Correcte tijd voor international users
- Daylight saving handling
- Audit trail nauwkeurigheid
Soft deletes pattern
Section titled “Soft deletes pattern”Implementatie
Section titled “Implementatie”In plaats van fysieke deletes gebruikt VEMAP soft deletes:
Closure stakeholders:
is_deleted BOOLEAN DEFAULT falsedeleted_at TIMESTAMP WITH TIME ZONEFiles:
is_archived BOOLEAN DEFAULT falsearchived_at TIMESTAMP WITH TIME ZONE (impliciet via triggers)Templates:
is_active BOOLEAN DEFAULT trueVoordelen
Section titled “Voordelen”- Audit trail: Historische data behouden
- Recovery: Ongedaan maken van deletes
- Analytics: Trend analyse over tijd
- Compliance: Voldoen aan data retention policies
Indexing filosofie
Section titled “Indexing filosofie”Strategisch indexeren
Section titled “Strategisch indexeren”Criteria voor nieuwe index:
- Query wordt >100x per dag uitgevoerd
- Query duurt >100ms zonder index
- Index grootte < 20% van tabel grootte
- Query gebruikt WHERE, JOIN of ORDER BY op kolom
Vermeden:
- Over-indexing (trade-off: write performance)
- Indices op low-cardinality kolommen
- Redundante composite indices
Partial indices
Section titled “Partial indices”Use case: Indexeer alleen subset van data
Voorbeeld:
-- Alleen actieve VKM plannen indexerenCREATE UNIQUE INDEX idx_vkm_plan_current_versionON files(closure_id)WHERE type = 'vkm-plan' AND is_current_version = true;Voordeel: Kleinere index size, snellere queries
Compliance & auditing
Section titled “Compliance & auditing”Data retention
Section titled “Data retention”Active data:
- All current projects en closures
- All user data voor actieve environments
Archived data:
- Gearchiveerde projecten: 7 jaar
- Email logs: 2 jaar
- Bounce events: 1 jaar
Audit trail
Section titled “Audit trail”Tracking per record:
created_at- Wanneer aangemaaktcreated_by- Door wie aangemaaktupdated_at- Laatste wijzigingupdated_by- Door wie gewijzigdarchived_at- Wanneer gearchiveerd (waar van toepassing)deleted_at- Wanneer soft deleted (waar van toepassing)
Change logging:
- Application layer logging van alle mutations
- CloudWatch logs voor database queries
- Slow query logging voor performance monitoring